

Decision graph for predictable behavioral analysis Part 1
The evolution of the used technologies and techniques in affiliate industry grows fast and therefore changes fast too. In fact, it is one of the most increasing and changing industry currently. Some years ago affiliate platforms worked with static banners written in HTML. The first so called retargeting algorithm was used 10 years ago. We all knows this concept from amazon, who used retargeting a long time, or rather still using it. For example if you buy an external hard drive amazon is still promoting external hard drives to you even weeks after the purchase. The second step was the using of predictable behavioral analysis algorithms, which does not dumb repromote advertise to you but rather check which one is fitting to your interest and suggesting similar products. Nowadays when you purchase an external hard drive you will get ads for other hardware products like CPU or graphic chips. The latest invention was an improvement of the original collaborative filtering algorithm. It does not only recognize your interest in order to match a third fitting interest group it also detects so called forwarding behaviors. In fact, if you are a lady around 30 and purchase sweet source combinations of products the affiliate industry most likely will promote baby products to you, because there is a change of up to 80% that you are pregnant. This last algorithm works with less than 100 target groups like we earlier discussed in another article.
In addition the usage of such algorithm increased the click rate from below 1% up to ~ 4%.
Nice history lecture, so what’s up with it?
Alright, let’s not focus the current mainstream. We started a project where we develop a new algorithm within the group of predictable behavioral analysis. But we won’t focus the topic matching of interests like in collaborative filtering but rather predict the upcoming decisions of a user. The meta level.
I don’t get it. What is the difference now?
It is just a small difference in the concept but it results in a major difference of the algorithm and outcome. Collaborative filtering techniques tries to find similar interests because the factual is close that the user will like similar topics to the one it already likes. This only takes into account related topics like hardware and software but not hardware and soft drinks. We want to take all possibilities into account by predicting the upcoming decisions of a user. Collaborative Filtering (CF) bypasses this by selection similar topics. And that is basically it.
How does this look like?
Let me illustrate this algorithm by using Workflow Modeling Language:
In addition, we created a gif for better visualization:
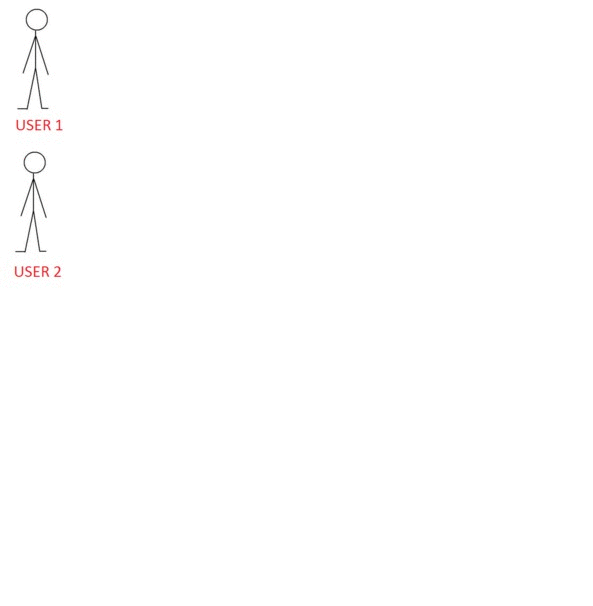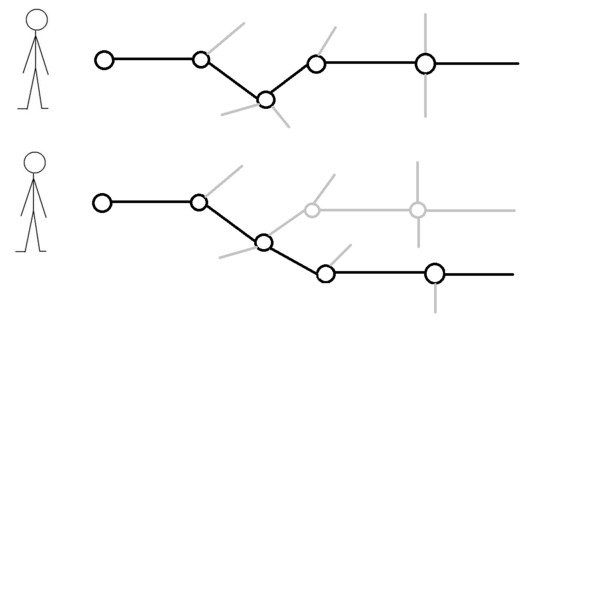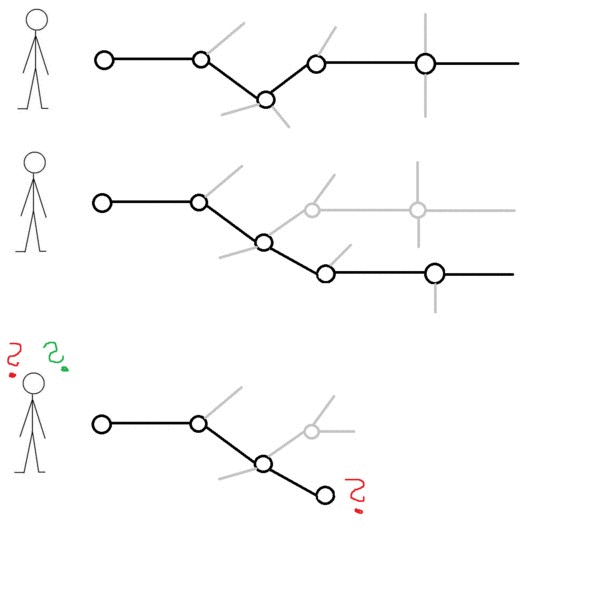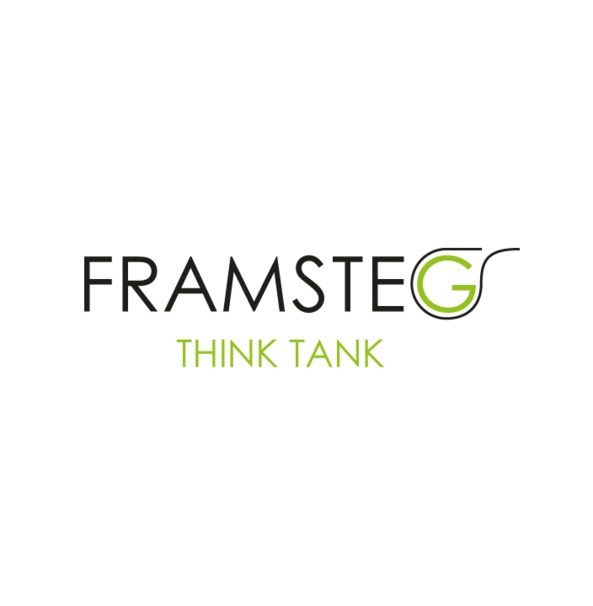
What is the origin of this idea?
The basic idea originate from the field of process mining. In process mining one uses mining algorithms in order to reproduce process models from logs. These logs were extracted from running business processes. During this stage of discovery one has also to deal with the topic of wrong or incorrect data called “noise”. Therefor researchers using techniques like genetic and heuristic mining algorithms. But that’s enough right here. More about the topic of process mining could be found right here. We developed a similar algorithm by adapting the target group and the different data setup and what we are doing now is mining the decision process of every user. These decision process are illustrated as workflow net or as decision node. And by comparing abstracts of these decision graphs we are able to find congruent behavioral patterns.
Results
With the first prototype we are able to generate a click rate of 5-6% but the algorithm’s performance is more than bad. In order to accomplish 10 requests / second we need 32 GB RAM & 20 Ghz for our in memory database and calculations. This goes back to the point that we generate for every user request its entire decision way but only need the next possible decision gate. Further our systems currently learns from every request, because almost all decision ways are unique. Therefor the learning part was more than exponential. With the current state we have more than 100.000 unique decisions ways for as target group. In addition to increase the performance we have to optimize some of these factors.
We will continue on optimizing this algorithm in order to access the mark of 7% .
A big thanks to our partners who provide us real data for testing purposes.
UPDATE: During the last month we were already able to increase our result set by 1% up to the benchmark of 6.5%. This goes back to the usage of linked list instead of vectors.
